
总结汇报:2025/12/16
总结汇报 2025/12/16
题外话:网站后端逻辑在这周进行了更新,现在的详细周报不再对文章加密,而是对分类进行加密
通过 Cookie 保存访问 Hash, 一旦成功访问该分类后,有效期内该加密分类下所有文章都可以免密快速访问
1 第一周
1.1 BasicVSR++
上次训练了一版数据是 BasicVSR 的,这是一个相对老一点的视频超分辨率的模型,他有一个优化版本,也就是 BasicVSR++
另外,上一次的训练中,有一些的不规范的地方,在此次更新中统一进行修改
- 划分更加合理的 test, validation, train 的数据集格式,规范区分验证和测试(比例是 90/5/5)
- 撰写主管优化 Loss 函数,并尝试添加到训练过程中(使用主观指标 LPIPS)
具体操作步骤撰写在详细报告中
在这一次的训练过程中发现了 BasicVSR++ 这类框架对 DDP 的多卡训练支持并不算好,甚至慢于单卡训练(或许是由于多卡对 CPU 造成的巨大压力,因为每一个卡都要分配 worker)
在添加完所有的代码,并测试可以正常运行后,于 2025/12/08 进行了第一次训练(预计约 4 天)
1.2 理论学习
学习了 L2 正则约束过拟合相关理论
2 第二周
2.1 BasicVSR++
事实就是训练并不算顺利,加入新 loss 后发生了梯度爆炸的问题
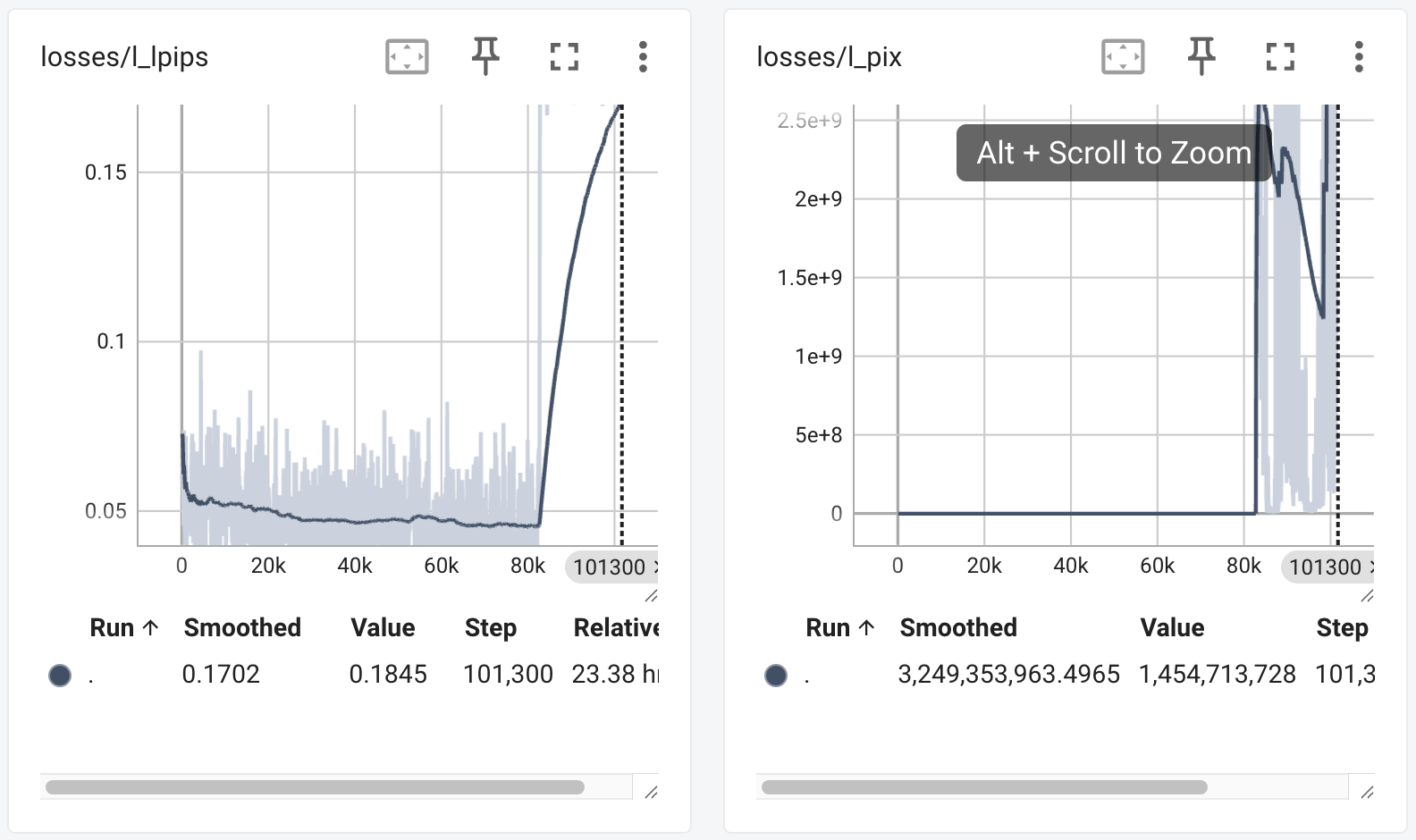
通过 4 轮 debug 和重启后,执行了以下操作:
- 调低了 LPIPS 指标 2 个数量级
- 加入 LPIPS 的梯度裁剪
- 分阶段对不同层进行梯度裁剪
成功控制了梯度,同时也提出了一个方向:在前期以 MSE 为主,后期以主观指标为主,同时我们也可以加入更多的主观指标,进行多目标优化。
主观指标在重启后可以看到进行了比较明显的下降


等待模型收敛后,可以测试主观优化的实际效果
2.2 文献调查
根据要求也同样进行了一些文献的调查工作,同时也对齐了一下前后处理的工作方向,总结一下 3 份文献:
- Towards High-Quality and Efficient Video Super-Resolution via Spatial-Temporal Data Overfitting:通过按空间与时间纹理复杂度划分视频 Chunk,并对每个 Chunk 进行过拟合,实现针对单视频/片段的高质量、高效率超分恢复。
- Enhancing Video Super-Resolution via Implicit Resampling-based Alignment:提出隐式重采样对齐机制,缓解传统对齐中的插值采样损失,可嵌入现有 VSR 框架,在几乎不增加计算量的情况下显著提升对齐与重建效果。
- Classic Video Denoising in a Machine Learning World: Robust, Fast, and Controllable:将视频去噪拆分为噪声建模与去噪两阶段,利用稳定的噪声画像实现快速、可控且低算力需求的高效去噪。
2.3 理论学习
学习了 Weight Decay, Dropout 来控制过拟合问题
2.5 下一步
- 可以研究一下多目标优化的方向,如多主观指标的优化 loss
- 考虑一种随着训练推进,MSE 权重逐渐衰退,让主管优化方向主导
- 考虑搜寻压缩噪声和普通的自然噪声之间的区别,并调查一下压缩噪声相关模型的操作
总结汇报:2025/12/16
https://rainerseventeen.cn/index.php/Summary-Report/47.html
评论已关闭